# 5 Writing Tips to Make Your Content Machine Readable! Learn 5 essential machine readable content writing tips using clear syntax and entity-rich language to aid NLP processing and boost authority.
AnimaVersa – In the early days of Google’s BERT update, many content strategies were flipped on their head. It was the moment search algorithms stopped being mere pattern matchers and truly started understanding context. That transition was powered by a linguistic revolution: Natural Language Processing (NLP) systems evolving from simple bag-of-words models to complex semantic interpreters that prioritize meaning, nuance, and structure.
When LLMs—the generative models now driving AI search and conversational interfaces—produce nonsensical, yet perfectly grammatically correct, fabrications (the dreaded “hallucination”), it often stems from ambiguity in their training or source data. If the input text lacks clear context or logical flow, the model defaults to a statistically plausible but factually ridiculous output. This inherent limitation in reasoning ability when context is fractured highlights the absolute necessity for content producers to eliminate linguistic noise.
Our responsibility as modern content creators is no longer just charming the reader; it is structurally engineering our language to be so unambiguous that advanced search algorithms and generative AI can map its true semantic meaning with 100% confidence. This is the difference between unstructured text and a high-fidelity data source.
We must adopt machine readable content writing tips as foundational strategy. This means intentionally writing in a way that smooths the path for computational linguistics, statistical modeling, and deep learning processes, ensuring your high-value information isn’t just found, but reliably extracted and cited. Here are five strategic linguistic adjustments that transform your content into a powerful, machine-ingestible asset.
1. Clear Syntax Is Your Parse Tree’s Best Friend
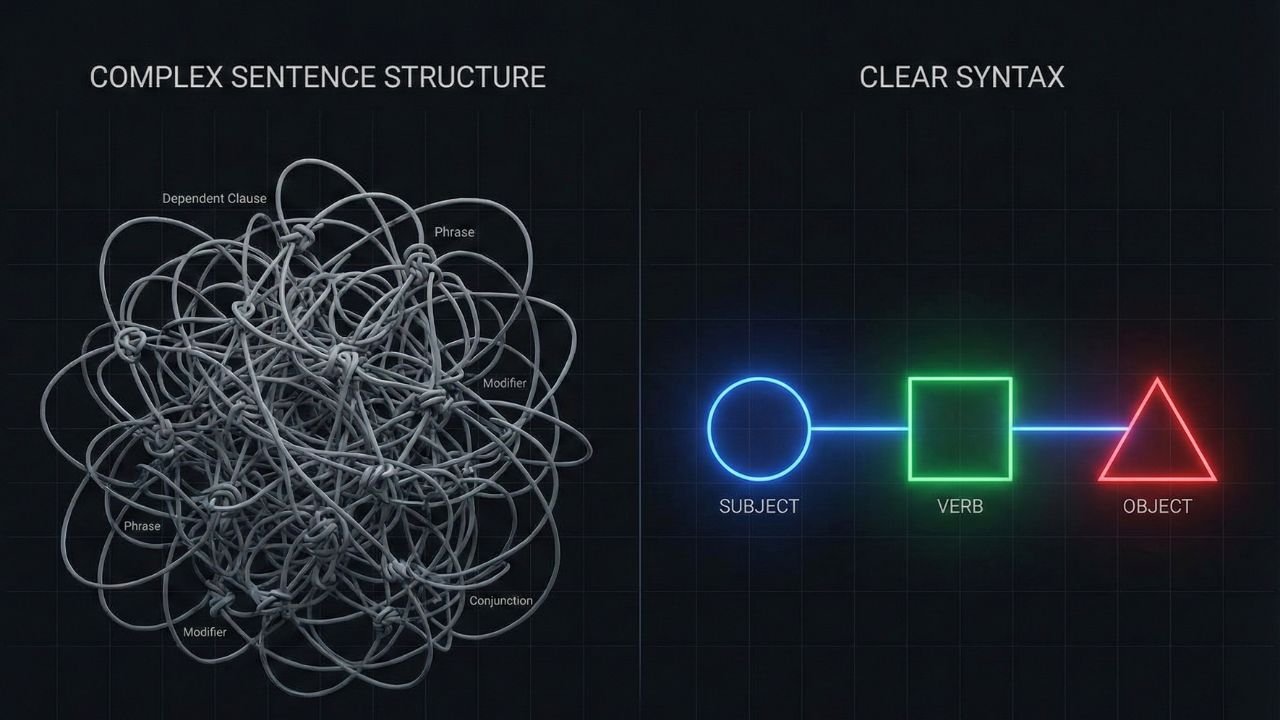
To an NLP system, your sentence is not a sequential line of words; it is a structural diagram. Natural Language Processing systems rely heavily on syntactical analysis—the process of parsing the text to apply grammatical rules and determine the precise function of every word. The output of this analysis is typically a ‘parse tree,’ a visualization of the hierarchical and relational structure of the sentence.
If a human reader encounters an overly long, convoluted sentence—say, one filled with multiple nested clauses—they might re-read it to grasp the intended meaning. A machine, however, sees this as a probabilistic puzzle. Poor or ambiguous syntax means that several plausible parse trees might be generated, forcing the machine to assign a confidence score to each possible interpretation. When confidence is low, the data is deemed less reliable for high-stakes tasks like generating a featured snippet or contributing to a knowledge base.
This is why clear syntax is critical. NLP parsing usually involves two methods: Constituency Parsing, which groups words into phrases (like noun phrases or verb phrases), and Dependency Parsing, which focuses on the explicit grammatical relationships between words, identifying which words are dependent on others (e.g., identifying the main subject and verb). Modern systems lean heavily on dependency analysis to understand the core participants and actions in a sentence, which is fundamental to deep semantic parsing.
The Power of S-V-O Structure
The single most effective strategy for enhancing machine readability is prioritizing active voice and the classic Subject-Verb-Object (S-V-O) structure. When the core components of meaning—the actor, the action, and the receiver—are placed close together, the dependency parsing process becomes straightforward. The machine quickly and reliably links the necessary nodes (words) together, yielding a single, high-confidence parse tree.
Conversely, long sentences broken up by multiple subordinate clauses, especially those that place the verb or object far from the subject, introduce ambiguity. Consider a sentence where the modifier is misplaced; the machine must decide which entity the adjective or adverb relates to. By limiting subordinate clauses and maintaining tight S-V-O sequences, you provide clean, predictable pathways for the algorithm. This highly efficient structure is paramount for writing for AI crawlers, as it minimizes the computational resources and processing time required for comprehension. When you intentionally write with this precise, streamlined structure, you are meeting the technical demands of seamless semantic search syntax.
2. Glue Your Logic: The Mathematical Role of Connectors
In the world of contemporary content, we must recognize that words are not just symbols; they are data points represented numerically as vector embeddings. These vector embeddings capture the semantic meaning and contextual relationships of words and concepts in a high-dimensional space. When two concepts are semantically similar—like “iPhone” and “Apple Inc.”—their vectors point in a similar direction, a similarity measured by cosine similarity.
However, similarity alone is insufficient. We need to define how concepts relate to each other—causally, contrastingly, or sequentially. This is where the simple yet profound power of logical connectors, often called transition words (e.g., therefore, consequently, however, in addition), comes into play. These phrases are the mathematical signposts that guide the AI through the semantic landscape of your text.
Defining Relationships in Vector Space
When an NLP model processes a transition word, it receives an explicit, high-signal instruction regarding the relationship between the current sentence’s vector and the previous one’s vector. These connectors act as logical operators in the data array:
- Causality Markers: Phrases like “as a result,” “consequently,” or “therefore” explicitly inform the model that the upcoming concept vector is the direct outcome or effect of the preceding concept vector. This is critical for establishing cause-and-effect relationships, a sophisticated form of reasoning that, when absent, can lead to the “limited reasoning” errors and logical hallucinations seen in LLMs.
- Contrast and Concession: Connectors such as “however,” “conversely,” or “despite this” guide the model to understand when two related concepts exist in opposition or tension. In a vector space, this ensures the vectors, while perhaps near each other (because they relate to the same topic), are processed with the knowledge that they represent diverging facts or viewpoints. This dramatically improves faithfulness and prevents the AI from generating contradictory or inconsistent outputs.
- Reinforcement and Sequencing: Connectors like “in addition,” “furthermore,” or “firstly” instruct the AI to group subsequent information closely with the preceding facts, reinforcing the importance of shared attributes.
Using robust logical connectors for SEO ensures that your document flows seamlessly for human readability , but, more importantly, it provides the explicit logical links necessary for generating strong, reliable vector embeddings. By mastering these explicit connective phrases, you dramatically improve the accuracy and efficiency of NLP content optimization.
3. Name Things Precisely: Entity Density, Not Keyword Stuffing

The era of merely matching keywords is over. Modern semantic search systems are fundamentally concerned with entities—real-world concepts, places, people, or things that possess verifiable attributes. These entities form the building blocks of Google’s Knowledge Graph, an index that connects concepts into a comprehensive web of understanding.
When engaging in entity-rich writing, the strategic focus shifts from maximizing the repetition of a phrase to ensuring the comprehensive coverage of a topic and its related components. This strategy is about demonstrating genuine, thorough domain knowledge, which signals authority and reliability to search engines. If your content discusses “climate change,” it must naturally include related entities like “carbon emissions,” “Paris Agreement,” “IPCC reports,” and key scientists in the field.
The key distinction here lies in density versus stuffing. Keyword stuffing was spammy, repetitive, and often unnatural. Entity density involves embedding a topic with its necessary constellation of related concepts, attributes, and definitions. This holistic approach proves that the content creator possesses true expertise, as noted in analyses comparing keyword targeting versus broader entity optimization.
Strategy for Entity Mapping
To write for the Knowledge Graph, precision is paramount.
First, Ensure Naming Consistency and Specificity: When discussing a subject, use specific forms that clearly distinguish between similar entities. If you mention “The Eiffel Tower,” maintain that name (or a clear pronoun) consistently, and ensure you mention its context (Location: Paris, Architect: Gustave Eiffel). This consistent referencing maximizes connectedness, allowing search algorithms to accurately group information under a single, central entity node.
Second, Define Attributes Naturally: Every time a critical entity is introduced, the surrounding sentences should function to define its attributes. For instance, stating “Amazon Web Services (AWS), the global leader in cloud computing infrastructure, announced a new service…” clearly links the entity (AWS) to its key attributes (global leader, cloud computing) within the sentence flow. This continuous attribute definition is what allows AI to gain deeper context and construct a high-fidelity representation of the entity.
By ensuring your content uses a high density of relevant entities and consistently defines their attributes, you solidify the topic’s position in the semantic vector space, improving its relevance and overall authority, measured partially through metrics like cosine similarity. This is how sophisticated writers move past mere topic coverage and truly engage with semantic models.
4. Explicitly Define Relationships: Writing for Relation Extraction
If clear syntax ensures your sentences are structurally sound, and entity density ensures the proper nodes are present, then the fourth strategic move—explicit relationship definition—is about forging the strongest possible edges between those nodes. This is the process of relation extraction, where algorithms identify the precise nature of the link between two entities (e.g., Entity A is the CEO of Entity B).
For high-confidence data extraction, the relationship cannot be implied; it must be stated using strong, unambiguous verbs. In NLP research, models are trained by explicitly marking the terms they need to analyze within a sentence, focusing the algorithm’s attention on the relationship verb between them. We, as content strategists, must mimic this marking process through deliberate linguistic choice.
Harnessing the Declarative Verb
The verb is the most critical word in the sentence for relation extraction. It serves as the label on the edge connecting two entities in a Knowledge Graph.
- Avoid Passive Voice: Passive constructions obscure the actor and complicate the identification of the causal relationship. Active voice requires a Subject-Predicate-Object structure, which is the foundational format for a factual “triple” (e.g., Subject [is related by] Predicate [to] Object).
- Select Strong, Contextual Verbs: Use verbs that define the exact relationship. Instead of saying “Einstein was involved with physics,” say “Einstein developed the theory of relativity.” Verbs like invented, founded, produced, described, caused, defined, or is a subset of are powerful extractors.
- Maximize Connectedness: Ensure that, within the context of the article, a person or concept is consistently tied to its primary role or achievement. For example, if discussing the history of AI, ensure that Alan Turing is not just a mentioned name, but explicitly tied to “the Turing Test” or “foundational computer science concepts.”
This precision ensures that your sentences are instantly recognizable as definitional statements. When a search system or LLM seeks high-confidence facts for an answer, it prioritizes content where these relational triples are clearly articulated. This commitment to precise articulation provides highly effective NLP content optimization, ensuring your expertise is not overlooked due to linguistic fuzziness.
5. Structure Answers for Extraction: Leveraging Q&A Patterns
The most practical step in making content machine readable is organizing information in the way AI prefers to consume and deliver it: as answers to explicit questions.
Modern generative AI and semantic search engines function fundamentally as sophisticated question-answering systems. A user query, whether spoken to a voice assistant or typed into Google, is a signal for the machine to retrieve the most concise, authoritative, and factually accurate response. You can radically increase your content’s visibility and citation likelihood by aligning your article structure with this AI demand. This is the ultimate technique for writing for AI crawlers.
The strategy involves a twin focus: linguistic formatting and technical markup.
The Linguistic Structure: Question-First Content
Every major section or subheading that addresses a core informational need should be framed as a direct question.
- Use H2/H3 Tags as Queries: Instead of using a categorical header like “The Mechanism of Dependency Parsing,” use “How Does Dependency Parsing Determine Semantic Meaning?” This immediate contextual clue tells the machine that the following text serves as the definitive answer.
- The Perfect Snippet Sentence: Crucially, the very first sentence immediately following that question heading must be the complete, concise, and direct answer. For example: “Dependency parsing determines semantic meaning by mapping the grammatical relationships between words, identifying the core subject, verb, and direct object.” This sentence should be engineered to be a perfect standalone snippet, capable of being extracted for a People Also Ask (PAA) box or a featured snippet.
If the concept you are explaining is so complex that you cannot summarize the answer in the first declarative sentence, the content is likely not yet optimized for immediate machine extraction.
The Technical Structure: Schema Markup
Once the content is linguistically structured, it must be technically marked up. Structured data, such as QAPage or FAQPage Schema, is a standardized format that provides explicit context to algorithms. It is the language that tells AI exactly what your content is about.
By implementing FAQPage schema, you are explicitly informing AI platforms: “This text block is the Question, and this corresponding text block is the Answer”. This removes all guesswork. Search engines actively look for this markup to understand content relationships, extract accurate information, and identify citation-worthy sources, ensuring the content is eligible for rich results on the search results page. This commitment to clear structure and explicit markup is one of the most effective machine readable content writing tips available today, turning your passive document into an active data resource.
To achieve maximum visibility and authoritative standing in the semantic search era, content must be engineered for both human pleasure and machine efficiency.
- Syntax Clarity: Prioritize active voice and S-V-O structures to facilitate clean, high-confidence Dependency Parsing, which minimizes the cognitive load on NLP systems.
- Vector Guidance: Employ logical connectors (therefore, however) as mathematical instructions to define causality and relationship, strengthening the accuracy of contextual vector embeddings.
- Entity Precision: Shift focus from raw keyword counts to comprehensive coverage and consistent, precise naming of entities and their associated attributes to build authority within the Knowledge Graph.
- Relational Verbs: Use strong, contextual verbs in active voice to define factual triples, ensuring the machine accurately extracts the relationship between key entities.
- Structured Q&A: Frame content sections as direct questions and provide concise answers immediately, then reinforce this structure using Schema markup (FAQPage/QAPage) for optimal snippet and generative AI extraction.
Want to deepen your understanding of the technical side of semantic content and content vectorization? Be sure to check out other articles by Raven S. Follow and like AnimaVersa for more cutting-edge content strategies across all platforms
Raven S., is a technologist, professional coder, and software enthusiast with a singular vision: to bring transparency, depth, and genuine expertise to tech journalism.